Introduction to Natural Language Processing (NLP)
Definition and Overview
What is Natural Language Processing (NLP)?Natural Language Processing (NLP) is a branch of artificial intelligence (AI) that focuses on the interaction between computers and human languages with the goal of enabling computers to understand, interpret, and generate human language in a meaningful and useful way.

You may also be interested in Artificial Intelligence as well.
How did Natural Language Processing (NLP) began?Early attempts at language processing involved rule-based systems, while recent advancements have been driven by machine learning and deep learning techniques.

Here's a simple example of rule-based Natural Language Processing (NLP):

Natural Language Processing (NLP) has a wide scope with applications across various domains including text analysis and understanding, sentiment analysis, language translation, chatbots, information retrieval, speech recognition, and synthesis.
We will check those elements in detail in the following sections.
What are the challenges of NLP?Natural Language Processing (NLP) faces challenges such as ambiguity, context sensitivity, and the need for substantial data and computational resources. Despite these challenges, NLP offers opportunities to automate tasks, enhance user experiences, and extract insights from large volumes of textual data.
What is the importance of NLP in AI?NLP is increasingly important for AI, as advancements in NLP are driving innovation in areas such as human-computer interaction, personalized content delivery, and knowledge discovery.
What is the difference between NLP and AI?NLP, or Natural Language Processing, deals with understanding and processing human language, while AI, or Artificial Intelligence, covers a wider range of concepts, including NLP, to create smart systems that can learn from data, make decisions, and solve complex problems, often imitating human intelligence in different areas.
Is ChatGPT an NLP?Yes, ChatGPT is an NLP, meaning it's a type of technology that helps computers understand and work with human language, like understanding text, generating responses, and assisting in various language-related tasks, such as answering questions and providing recommendations.
What is the difference between NLP and Natural Language Understanding (NLU)?NLP, or Natural Language Processing, involves a broader scope of tasks related to processing human language, including understanding, generating, and translating text, whereas Natural Language Understanding (NLU) specifically focuses on the comprehension aspect, aiming to extract meaning and context from text inputs for tasks like sentiment analysis or question answering.
What are the latest NLP advancements?The future of NLP holds promising trends and research directions including multimodal NLP, explainable AI, low-resource language processing, and integration with other AI technologies.
Importance and Applications
Here are seven important ways that Natural Language Processing (NLP) changes different parts of our lives significantly:
- Facilitating Human-Machine Interaction:
NLP plays a crucial role in facilitating Human-Machine Interaction by enabling natural and intuitive communication between humans and machines, powering applications like virtual assistants, chatbots, and voice-activated systems that respond to spoken commands.
- Improving Information Access and Retrieval:
NLP techniques improve Information Access and Retrieval by extracting insights and knowledge from vast amounts of text data, NLP makes information more accessible and actionable. This includes tasks such as search engine optimization, information retrieval, and document summarization.
- Enhancing User Experience:
NLP enhances User Experience by personalizing interactions, analyzing user-generated content, preferences, and behavior to power recommendation systems, content curation, and targeted advertising, thereby enhancing user satisfaction.
- Enabling Multilingual Communication:
NLP enables Multilingual Communication, bridging language barriers through tasks such as machine translation, language localization, and cross-lingual information retrieval.
- Supporting Decision Making and Analysis:
NLP supports Decision Making and Analysis by extracting insights and sentiment from textual data. This helps decision-making processes in domains like finance, healthcare, marketing, and social media analysis, improving strategic outcomes.
- Driving Innovation and Automation:
NLP drives Innovation and Automation by automating tasks traditionally performed by humans. This includes text generation, content moderation, sentiment analysis, and customer support automation, leading to increased efficiency and productivity.
- Addressing Societal Challenges:
NLP can address Societal Challenges by detecting misinformation, hate speech, and analyzing public opinion. By analyzing large-scale textual data, NLP contributes to tackling pressing social issues, fostering a safer and more informed society.
Fundamentals of NLP
Text Preprocessing
What is the purpose of text preprocessing?Text preprocessing serves to clean and prepare text data for analysis by removing unnecessary elements like punctuation and stopwords, converting text to lowercase, and stemming words, ensuring that the data is uniform and optimized for tasks such as sentiment analysis or text classification.
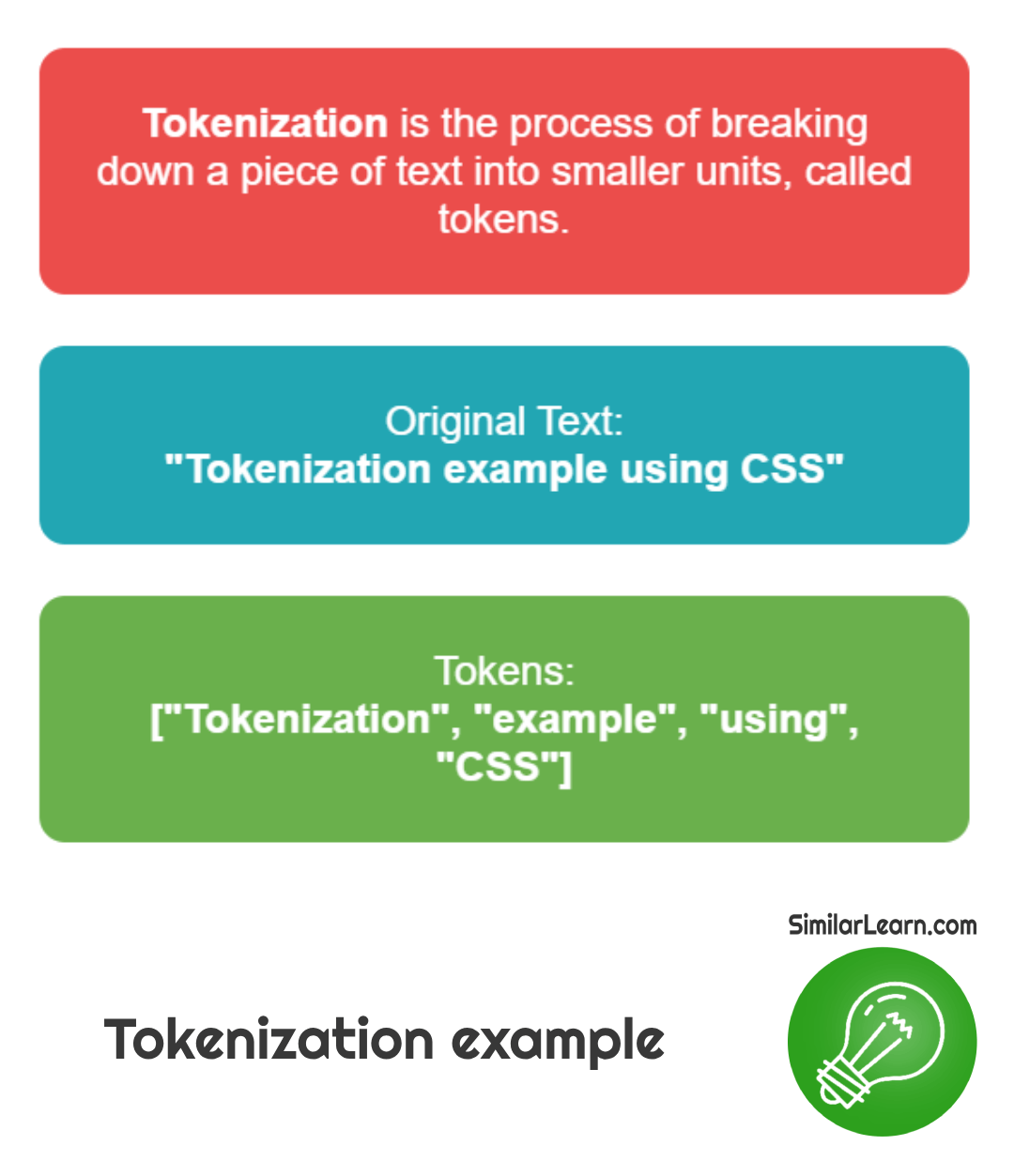
What is Tokenization?Tokenization breaks down a piece of text into smaller units, typically words or phrases, known as tokens, making it easier for computers to process and analyze the text.
Stopword removal involves eliminating common words like "the," "is," and "and" from text data to focus on meaningful words, thus enhancing analysis accuracy by reducing noise and improving the efficiency of natural language processing tasks like sentiment analysis or document classification.

Stemming simplifies words to their root form, disregarding variations like tense or plural forms, aiding in text analysis by treating similar words uniformly, thus improving accuracy in tasks such as search queries or sentiment analysis.
Check also our Guide To NLP Text Classification page.

Lemmatization is the process of reducing words to their base or dictionary form, ensuring that different inflected forms of a word are treated as the same word, aiding in text analysis tasks such as search and classification, ultimately improving the accuracy of natural language processing applications.

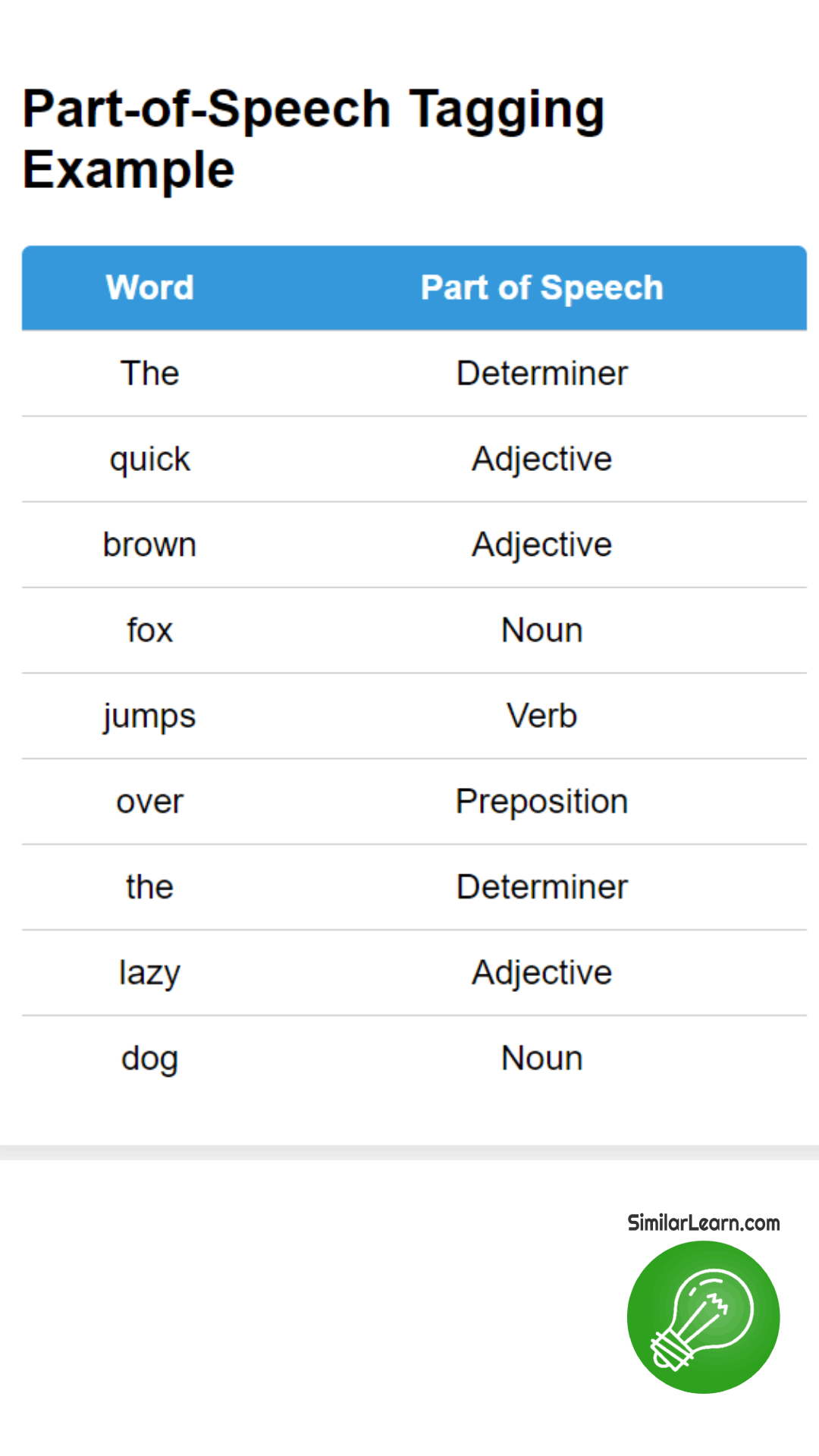
Part-of-Speech Tagging assigns grammatical tags like noun, verb, or adjective to each word in a sentence, helping computers understand the role of each word, supporting tasks like text analysis, translation, and speech recognition, thus improving accuracy and enabling more sophisticated language processing applications.
Feature Engineering
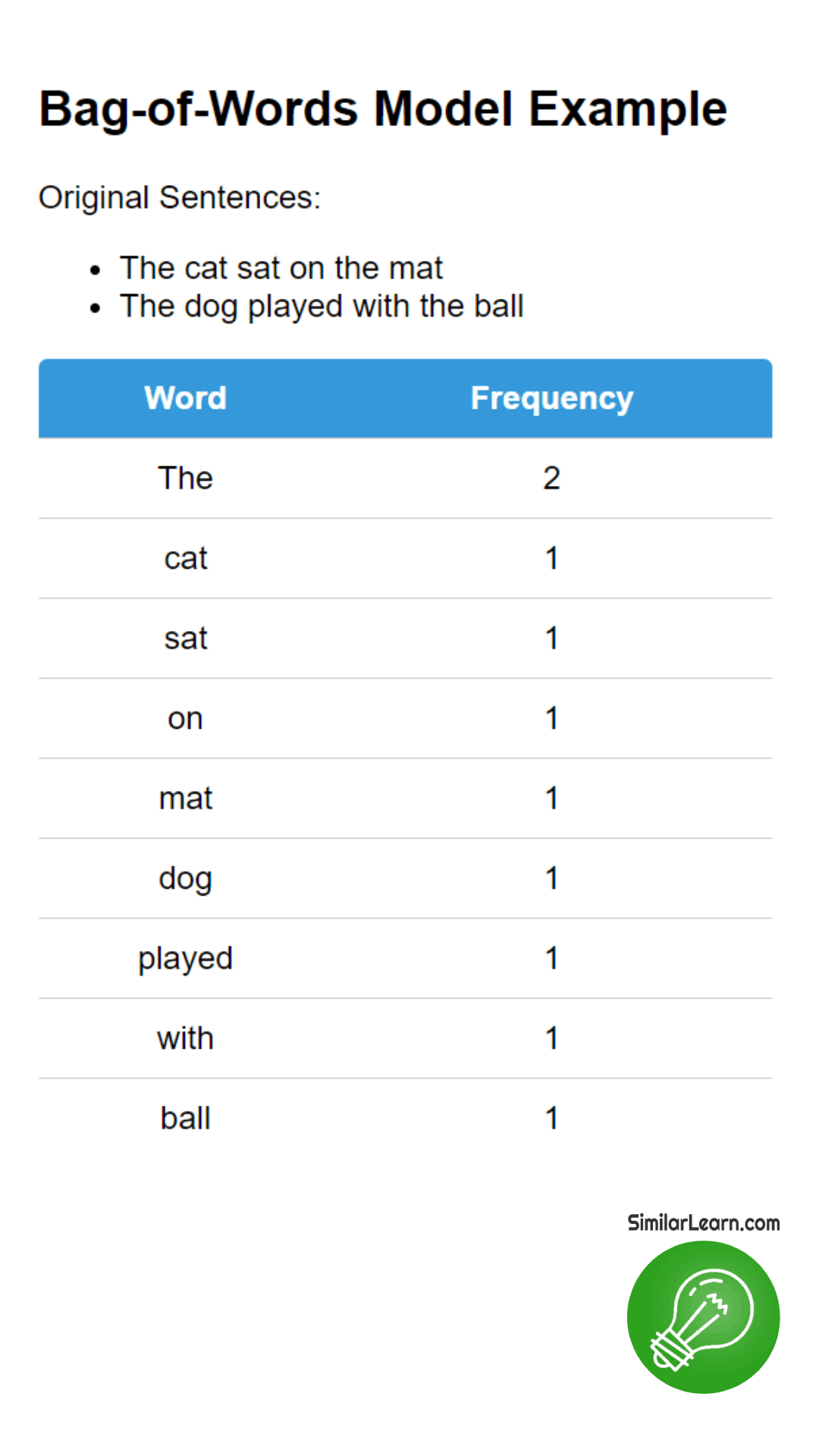
What is Bag-of-Words Model?The Bag-of-Words Model represents text as a collection of words without considering the order or structure, treating each word as independent and counting its frequency in a document, forming a numerical representation used in various natural language processing tasks like text classification and sentiment analysis for machine learning algorithms.
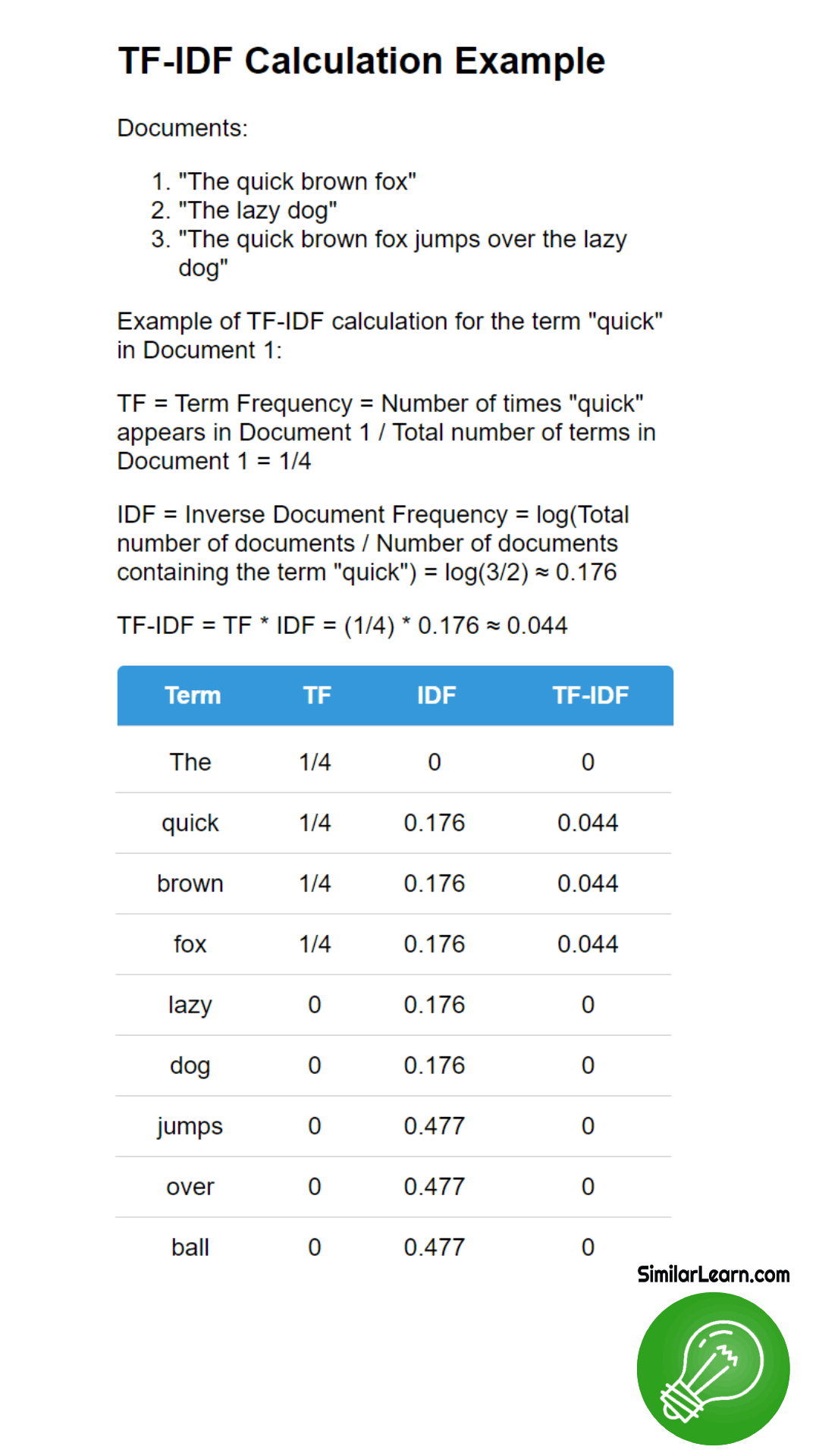
TF-IDF (Term Frequency-Inverse Document Frequency) is a numerical statistic used to evaluate the importance of a word in a document within a collection or corpus of documents, calculated by multiplying the term frequency (number of times a word appears in a document) by the inverse document frequency (logarithm of the total number of documents divided by the number of documents containing the word), assisting in information retrieval, text mining, and document classification tasks.
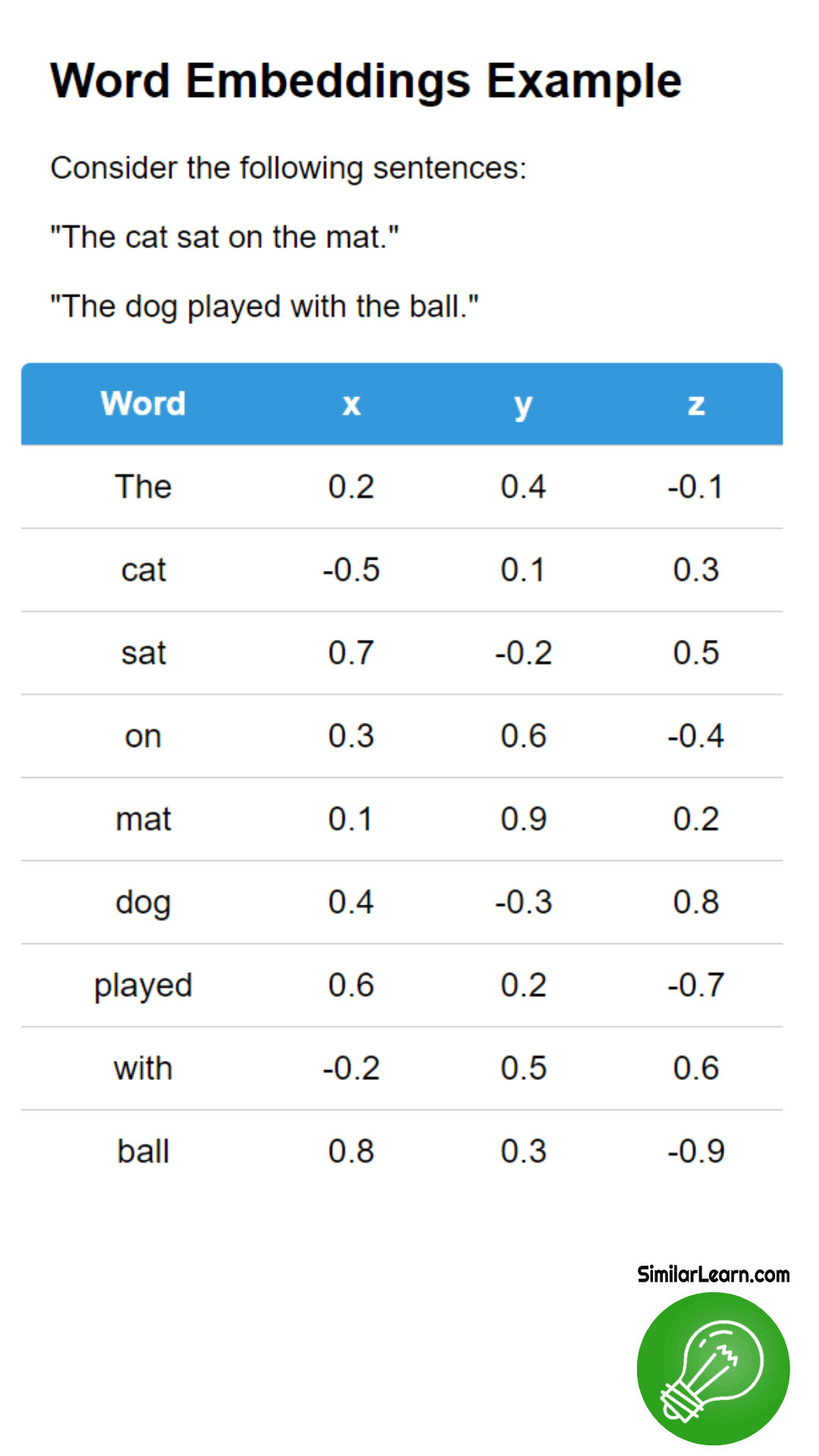
Word Embeddings, such as Word2Vec and GloVe, are techniques in natural language processing used to represent words as dense vectors in a continuous vector space, capturing semantic relationships between words based on their context in large corpora, helping in tasks like semantic similarity, text classification, and language translation.
You may also be interested in Artificial Intelligence as well.
NLP Techniques and Models
Rule-Based Methods
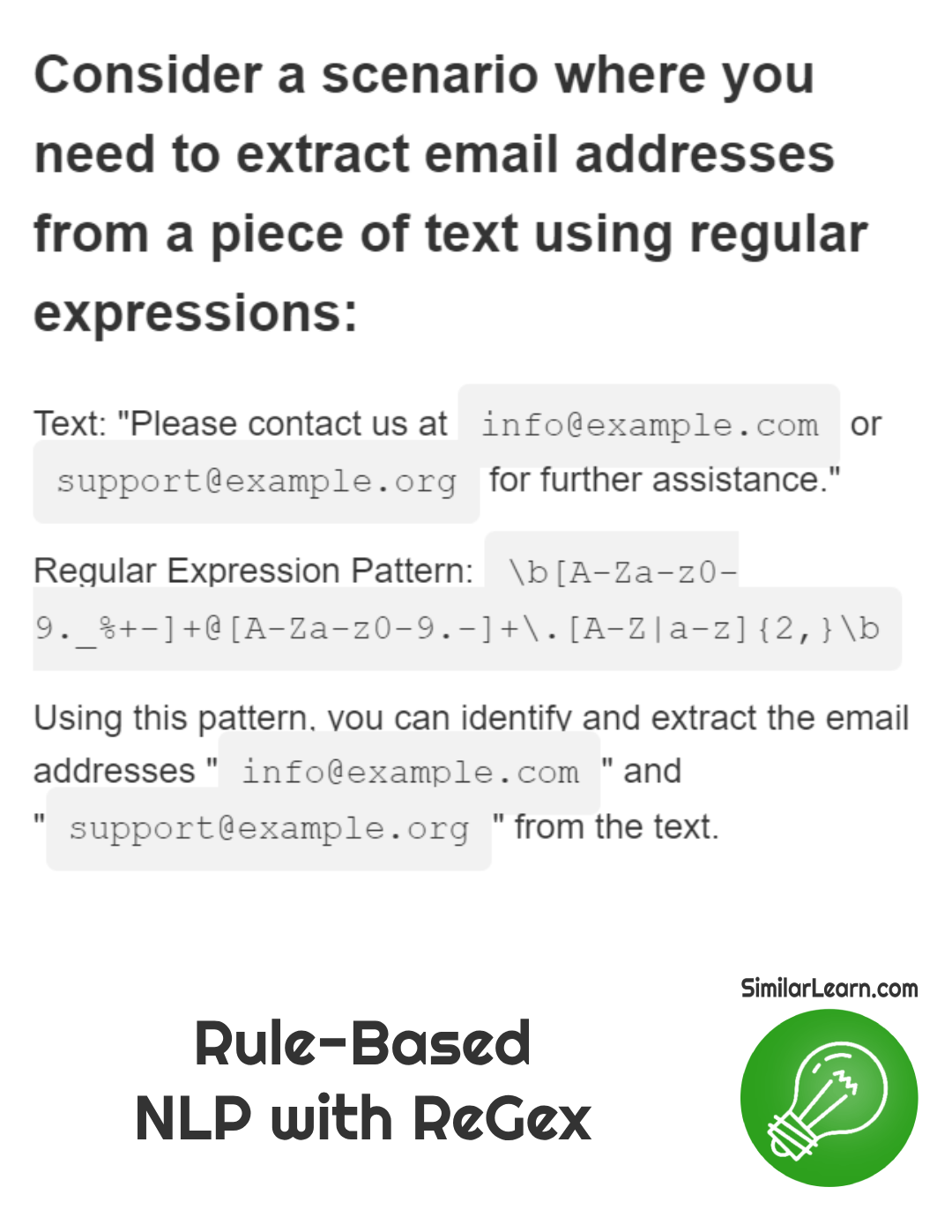
How are Regular Expressions used in Rule-Based NLP?Regular expressions in rule-based NLP are patterns of characters used to search and manipulate text data, allowing tasks like extracting specific information (like emails or phone numbers) from text, identifying patterns (such as dates or URLs), and replacing or formatting text based on predefined rules.
Syntax and grammar parsing are utilized in rule-based NLP by analyzing sentence structure and language rules, aiding in understanding word order and relationships, enabling the extraction of meaningful information from text, contributing to accurate language comprehension, and facilitating tasks such as information retrieval and text generation.

Statistical Methods
What are Hidden Markov Models (HMM)?Hidden Markov Models (HMM) are statistical models representing sequences of observable events where underlying states are hidden; they estimate the probability of transitioning between states based on observed data, widely used in speech recognition, bioinformatics, and natural language processing for tasks like part-of-speech tagging and named entity recognition.

Conditional Random Fields (CRF) are statistical models used for sequence labeling tasks such as named entity recognition and part-of-speech tagging; they consider the dependencies among neighboring labels to assign probabilities to sequences, improving accuracy in tasks where context plays a crucial role, like natural language processing and bioinformatics.
Machine Learning Models
What is Naive Bayes?Naive Bayes is a classification algorithm used in machine learning. It assumes independence among features, meaning it considers each feature equally important and unrelated to others. It calculates the probability of a data point belonging to a certain class based on the probabilities of its features.
What are Support Vector Machines (SVM)?Support Vector Machines (SVM) are machine learning models used for classification and regression tasks. They find the best separation line or hyperplane between different classes of data points in a high-dimensional space. SVM aims to maximize the margin, the distance between the hyperplane and the closest data points, ensuring robustness in classification.
How do Recurrent Neural Networks (RNN) function?Recurrent Neural Networks (RNN) function by processing sequential data, like words in a sentence or frames in a video, through loops that allow information to persist, helping them remember previous inputs. They analyze data step by step, updating their internal state at each time step to generate outputs, making them effective for tasks requiring sequential understanding.
What are Convolutional Neural Networks (CNN) used for?Convolutional Neural Networks (CNN) are utilized in various tasks like image recognition, object detection, and classification in fields such as computer vision and pattern recognition, helping in tasks like identifying objects in images, recognizing faces, and even in medical imaging for diagnosis purposes.
What is the explaination of Transformer Models such as BERT and GPT?Transformer Models like BERT and GPT are advanced language processing tools that understand context in text, aiding tasks such as translation, summarization, and question-answering by considering relationships between words, enabling them to generate coherent responses and comprehend nuanced meanings in a wide range of languages and contexts.
Common NLP Tasks
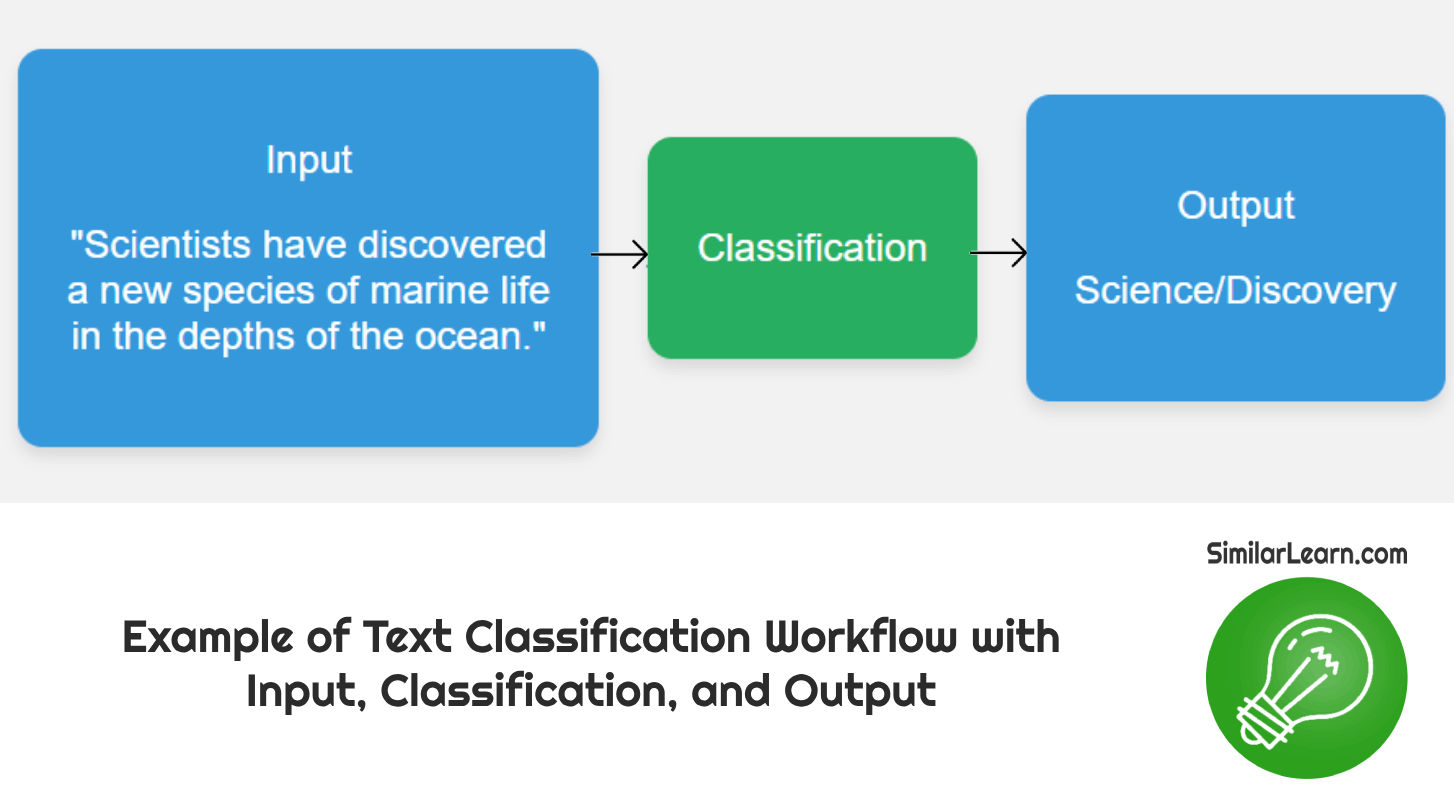
What is Text Classification?
Text classification involves categorizing pieces of text into predefined classes or categories based on their content, helping in tasks like spam filtering, sentiment analysis, and topic labeling by analyzing the words and patterns within the text to assign it to the most appropriate category or class.
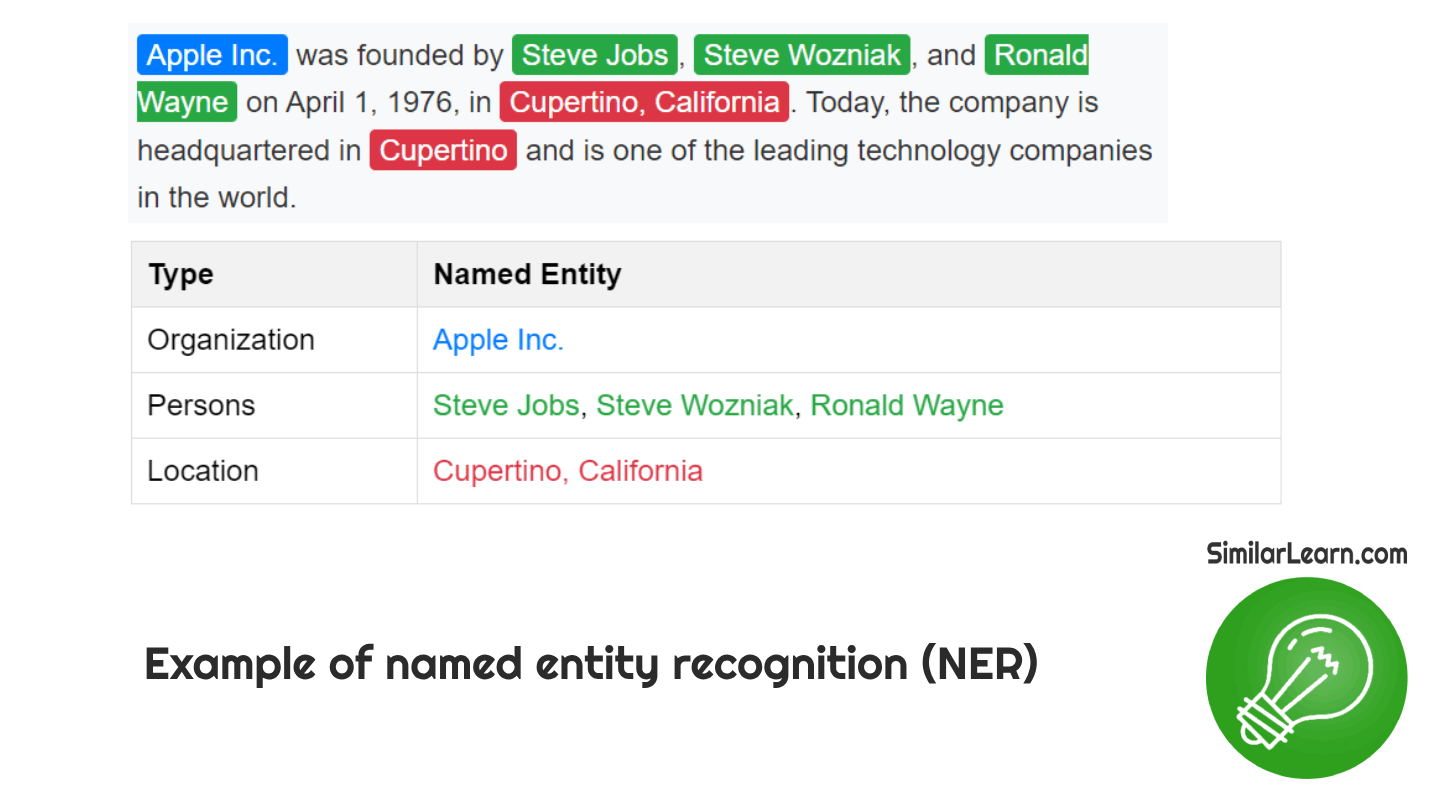
What is Named Entity Recognition (NER)?
Named Entity Recognition (NER) is a tool used in natural language processing that identifies and classifies specific entities within text, such as names of people, organizations, locations, dates, and quantities, assisting in tasks like information extraction, search engine optimization, and text summarization by pinpointing and categorizing important information.
What is Sentiment Analysis?
Sentiment analysis involves analyzing text to determine the emotional tone or attitude expressed within it, distinguishing between positive, negative, or neutral sentiments, aiding in understanding public opinion, customer feedback, and social media trends, helping businesses make informed decisions and tailor their strategies accordingly to enhance user satisfaction.

Check also our Guide To NLP Text Classification page.
What is Machine Translation?
Machine translation is the process of automatically converting text from one language into another, using algorithms and language models to analyze and translate phrases and sentences, facilitating communication between people who speak different languages, enhancing accessibility to information, and promoting global collaboration and understanding across diverse linguistic communities.

What is NLP Question Answering?
NLP Question Answering involves using natural language processing to understand questions posed in human language and providing accurate responses based on analyzing and comprehending the content of the question, assisting in tasks like information retrieval, virtual assistants, and automated customer support, thereby improving user interaction and access to relevant information.
What is NLP Text Summarization?
NLP Text Summarization condenses lengthy pieces of text into shorter versions while retaining the key information, helping readers grasp the main points efficiently, aiding in tasks like summarizing articles, documents, and emails, and facilitating faster comprehension and decision-making, thus improving productivity and accessibility to essential content.

Challenges and Considerations in NLP
Ambiguity and Polysemy
What is Ambiguity in NLP?Ambiguity in NLP refers to situations where a word, phrase, or sentence can have more than one meaning, causing confusion for computers in understanding human language accurately, which can lead to errors in tasks like language translation or sentiment analysis, posing a challenge in developing effective natural language processing algorithms.

Polysemy in NLP describes the phenomenon when a single word has multiple meanings, making it challenging for computers to interpret the intended sense accurately, which can affect tasks like language understanding and generation, necessitating sophisticated algorithms to discern context and select the appropriate meaning based on the surrounding words.
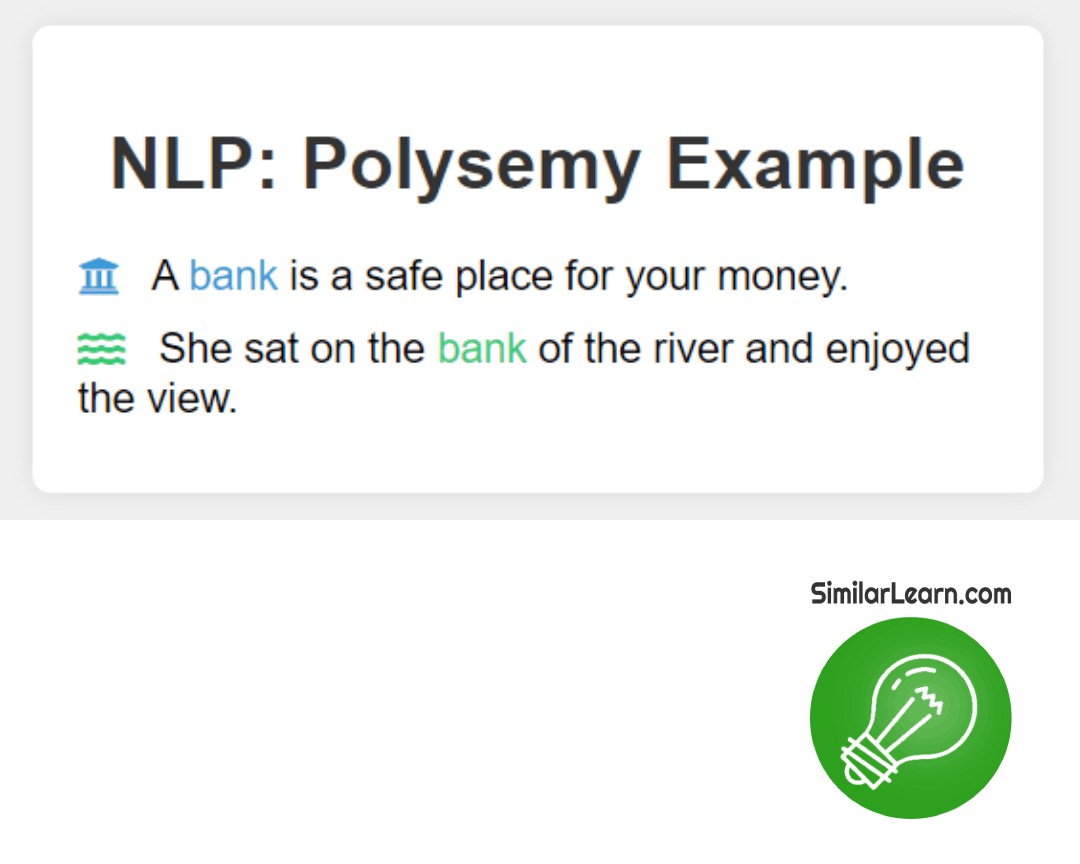
This complicates language processing, as the intended meaning may vary depending on context, requiring advanced algorithms to accurately understand and ensure clear communication in natural language processing tasks.
Data Quality and Bias
What is data quality in NLP?Data quality in NLP refers to how accurate and reliable the information is, ensuring that the data used for natural language processing tasks is free from errors, inconsistencies, and biases, which is vital for obtaining meaningful insights and building effective NLP models.
What is data bias in NLP?Data bias in NLP refers to the unfairness or inaccuracies present in the data used to train natural language processing models, leading to skewed results that may favor certain groups or perspectives over others, posing challenges for fairness, inclusivity, and reliability in NLP applications.
Domain Adaptation
Domain adaptation in NLP involves adjusting a model trained on one type of data to perform well on a different but related domain, such as transferring knowledge from news articles to social media posts, enabling the model to understand and process language effectively across diverse contexts and applications.
Ethical and Privacy Concerns
Ethical concerns in NLP involve ensuring that language processing technologies are used responsibly and fairly, addressing issues such as biased algorithms and their potential societal impacts, while privacy concerns revolve around protecting individuals' data and ensuring that sensitive information is not misused or exposed during language processing tasks and applications.
Best Practices and Resources
Data Acquisition and Annotation
What is data acquisition in NLP?Data acquisition in NLP is the process of collecting textual or spoken data from various sources like websites, books, or recordings, then organizing it into a format suitable for analysis, such as a database or text files, before proceeding with tasks like language processing, sentiment analysis, or machine translation.
What is Data Annotation in NLP?Data annotation in NLP involves labeling text data with tags or categories to teach machines to understand language, usually performed by humans who highlight entities, sentiments, or parts of speech in a given text, aiding in training algorithms to comprehend and process natural language more accurately and efficiently.

Model Evaluation and Metrics
What is model evaluation?Model evaluation in NLP is the process of assessing the performance of language models by measuring their accuracy, efficiency, and effectiveness in tasks such as text classification or sentiment analysis, helping researchers and developers determine the model's suitability for real-world applications.

Model metrics are numerical measures used to evaluate the performance of machine learning models, providing insights into how well they accomplish specific tasks like classification or regression, assisting users in understanding model behavior and making informed decisions about model selection and improvement without requiring them to give direct commands.
What are the tools and Libraries for NLP?
Here are the five most commonly used tools and libraries for NLP:
- NLTK (Natural Language Toolkit): It's a tool that helps with things like breaking down sentences, finding the meaning of words, and understanding the structure of language. People often use it to learn about how language works and to do research in areas like language processing.
- SpaCy: This tool makes it easy to do things like figuring out what type of word something is (like a noun or a verb), finding important information in text, and understanding how words relate to each other. It's popular because it's fast and simple to use.
- Gensim: Gensim is useful for finding patterns and similarities in big collections of text, like books or articles. It's great for tasks like figuring out what topics are being talked about in a bunch of documents or finding similar documents based on their content.
- TensorFlow: This is a tool for making and training models that can understand language. It's used by lots of people because it's flexible and powerful, making it possible to create really smart language models that can do things like translate languages or understand what people are saying.
- PyTorch: PyTorch is similar to TensorFlow but is known for being easy to understand and work with. People like using PyTorch because it makes it simpler to build and test language models, making tasks like translating languages or analyzing sentiment easier to accomplish.
Online Courses and Tutorials
SimilarLearn helps people learn about NLP and coding online. They offer courses and tutorials for those who want to understand NLP and learn how to code. It's for anyone who's curious about NLP and wants to pick up coding skills.
Where to find Research Papers for NLP?
You can find research papers for NLP on various platforms like Google Scholar, arXiv, or directly on the websites of universities and research institutions. Additionally, many NLP conferences publish their proceedings online, offering access to the latest research in the field.
What are the top NLP conferences?
The top NLP conferences are ACL (Association for Computational Linguistics), EMNLP (Empirical Methods in Natural Language Processing), and NAACL (North American Chapter of the Association for Computational Linguistics). These conferences bring together researchers to share and discuss their latest discoveries and developments in language technology.
Other Directions in NLP
Multimodal NLP
Multimodal NLP combines text with other forms of data like images or audio, enabling machines to understand and generate content across multiple modalities, enhancing communication and interaction by incorporating visual and auditory cues alongside text, which improves tasks such as captioning images, generating descriptions, or assisting visually impaired individuals in understanding multimedia content.
Explainable AI in NLP
Explainable AI in NLP helps humans understand how AI models make decisions by providing insights into the reasoning behind their outputs, ensuring transparency and trustworthiness in applications such as sentiment analysis or language translation, allowing users to comprehend and validate AI-generated results, which fosters confidence and facilitates collaboration between humans and machines.
Low-Resource and Multilingual NLP
Low-resource and Multilingual NLP focuses on developing AI systems that can understand and process languages with limited data, facilitating communication across diverse linguistic communities by creating models capable of handling multiple languages, which enhances accessibility to technology and promotes inclusivity by addressing language barriers in various applications like translation and information retrieval.
Conclusion
In conclusion, Natural Language Processing (NLP) uses AI to help computers understand and interact with human language. It's vital for things like chatbots, sentiment analysis, and language translation. NLP faces challenges like ambiguity and needs lots of data and resources. But it's essential for making technology more user-friendly and efficient. With ongoing advancements and techniques like machine learning, NLP keeps improving and shaping the future of AI and human-computer interaction.
Check also our Guide To NLP Text Classification page.